 Tetrate Service BridgeVersion: 1.7.x
Tetrate Service BridgeVersion: 1.7.xArchitecture
The previous section covered what a service mesh is, and introduced Istio — the service mesh that powers Tetrate Service Bridge. This section is all about the architecture that makes up TSB.
You'll learn about:
✓ Our philosophy for reliable deployments, which motivates the TSB architecture
✓ The Data Plane - powered by Envoy
✓ The Local Control Planes - powered by Istio
✓ Tetrate Service Bridge's Global Control Plane
✓ Tetrate Service Bridge's Management Plane
✓ Understand why a management plane is needed
✓ Envoy Extensions in Tetrate Service Bridge
By the end, you should have a clear understanding of each of the elements of TSB's architecture and how they work together to help you manage your environment.
Deployment Philosophy
Building high availability systems is incredibly challenging and expensive. The one tried-and-true technique we know of is to build around failure domains. A failure domain is the section of your infrastructure that is affected when a critical system fails.
There are a ton of failure domains in any given deployment; to name just a tiny sample:
- Physical failures: the host running your application fails (overheats, loses power, top of rack switch failure, etc), the rack your host is on fails (data center network failure), the hard drive your application is writing to fails, there's not enough resources in one place to schedule your job
- Logical failures: you misconfigure the deployment of your application (wrong ports, fat finger a configuration, etc), the serving framework your application is written with has a security vulnerability, you misconfigure your application itself
- Data failures: the database for your application has bad data, had a bad update (misconfiguration, botched binary update, etc), replication failed or lagged, backup failed (or wasn't persisted, or was persisted for too little time to be useful)
The fundamental way we build reliable systems is to group the sets of failure domains the system straddles into a silo, then replicate that silo as multiple independent instances. The overall reliability of the resulting system depends on how independent we can make the replicas. In practice there is always some interdependence, and minimizing it is always a trade off of cost against availability.
Physical Failure Domains
In modern cloud environments, the set of physical failure domains we need to worry about has been grouped into an easy handle to reason about, the availability zone. However, demonstrating the cost-vs-availability trade-off, we know that availability zones are not always truly isolated from each other (cloud provider outages demonstrate this all too frequently).
Therefore cloud providers group sets of availability zones into a higher level failure domain called a region. In practice it's not uncommon for multiple availability zones in the same region to fail, but it's incredibly rare for multiple regions to fail.
So with availability zones and regions in hand as the physical failure domains to reason about, we're left to think about the logical failure domain.
Logical Failure Domains
Logical failures largely depend on our own application architecture, and tend to be much more complicated to reason about. The key pieces we need to think about as an application developer is our application's deployment, configuration, data, dependencies, and how it's exposed (load balancing, DNS, etc).
In a typical microservice architecture, we build our applications to consume a cloud-provider database, run it using cloud provider primitives across availability zones in a single region (using Kubernetes, VM auto scaling groups, Container-aaS offering, and so on), and talk to dependencies deployed in the same region as much as we can; when we can't we go to a global load balancing layer like DNS first. This is our silo of failure domains, and we replicate it into other regions for availability (handling data replication somehow - this is a hard problem and a common failure domain cutting across silos).
Keep it Local
One of the easiest ways to create isolated silos without coupled failure domains is to run independent replicas of critical services in each silo. We could say that these replicas are local to the silo — they share the same failure domains (including physical ones, in other words they're "nearby").
We follow this "keep it local" pattern in Tetrate Service Bridge too: we run an instance of the Istio control plane in every compute cluster you're running applications on. In other words, we deploy Istio so its physical failure domains align with your applications'. Further, we make sure these instances are loosely coupled and don't need to communicate directly with each other, and minimize any communication they need to do outside of their silo.
This means each cluster you're running — whether it's a Kubernetes cluster, a set of VMs, or bare metal machines in your data center — is an island. The failure of one won't cause failures in the others. What's more, because the control plane is local to the cluster, it has knowledge of what's happening and when there is a failure, it can continue to keep its portion of the mesh behaving as best as possible with the context it has locally.
With this base primitive in hand, we can already start to build more reliable systems by simply failing over across silos holistically: if anything is wrong in a silo, just ship all traffic to a different silo until we've fixed the problem.
But to take it to the next level, what we'd really like to do is facilitate communication across silos when part fails, rather than failing over the entire thing. To do this, we need to communicate across our silos.
Facilitating Cross-Silo Communication
Keeping it local give us a set of silos that are available, but not interconnected. This results in waste, and makes failover operations painful.
What we often want to enable is finding a healthy instance of our dependency, even if it's not in our local silo, and route requests to it. For example, if we have a bad deployment of a backend service in one cluster, we'd like for the front-end to fail over to the existing deployment in our second cluster, rather than just fail user traffic because its local backend is unhealthy. Today to facilitate this applications often "hairpin" traffic, going out to their global load balancing system and back in, even if the application they want to communicate with is running nearby!
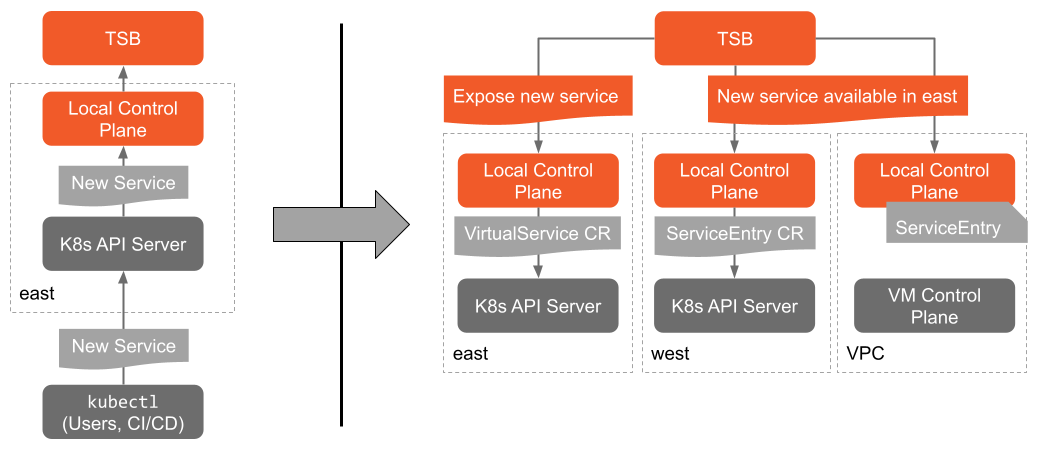
TSB facilitates cross-silo communication for applications while minimizing the configuration synchronization that's required across Istio control plane instances with its global control plane. It publishes the addresses of the entry points for each cluster in the mesh, as well as the set of services that are available in that cluster, to each Istio instance managed by TSB. When a service fails locally, or a local service needs to communicate with a remote dependency, we're able to direct that traffic to a remote cluster that has the service we need, without the application itself needing to worry about where the dependency lives.
One example we like to use to describe what we're doing here is the internet. You have total knowledge of your local network, and to get from your machine to hosts on other networks you use routes published by BGP. These routes tell us what local gateway to forward traffic to reach a remote address. In our setup, each Istio control plane instance has total knowledge of its local cluster. The global control plane fills in the role of BGP, publishing "layer 7 routes" that tell Istio which remote Gateways (other Istio clusters in the mesh) to forward traffic to to reach a remote service.
Overall Architecture
Conceptually TSB is comprised of four layers: the data plane, local control planes, the global control plane (typically called the "Cross Cluster Control Plane" or "XCP" in these docs), and the management plane.
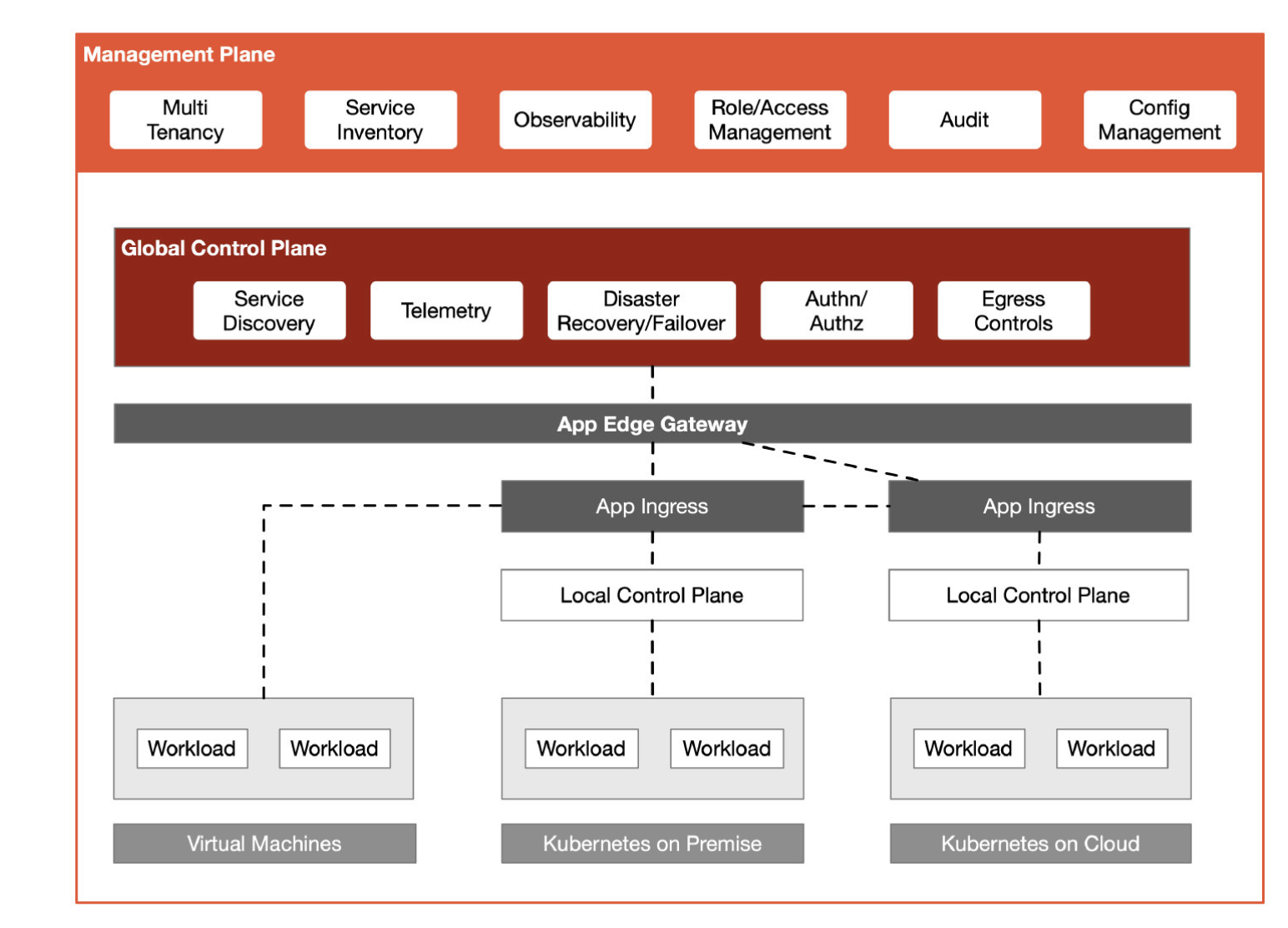
At the leaf of our architecture, next to every application instance and acting as ingress and egress proxies, we have our data plane. Envoy is the proxy used in TSB, and these proxies handle the bits-and-bytes of your application's traffic. They're the spot where we can enact traffic policy, enforce security policy, and report metrics.
The local control planes are deployed where your applications run: in their Kubernetes clusters, in your VM VPCs, and so on. The goal is to align the failure domains of this control plane with your applications'. This local control plane is a deployment of Istio alongside the Tetrate local control plane, XCP Edge, which configures that Istio instance in that environment. This layer implements all the baseline service mesh features, like service identity and encryption in transit, producing metrics for applications, and doing runtime traffic routing.
The global control plane links the separate local control plane instances into a coherent mesh by pushing configuration to each local control plane. The Global Control Plane primarily handles two types of configuration: mesh configuration from users (like traffic routing or security policy), and runtime service discovery data across clusters to facilitate failover and disaster recovery for applications running on TSB.
The management plane is the place where users interact with TSB: it's where your application teams can monitor and manage their applications; your platform team and understand the state of the system, perform upgrades, and enforce policy; and your security team can implement runtime controls for applications in your organization. This layer provides multitenancy — keeping your teams isolated and safe from each other while ensuring they can move as fast as they want — as well as audit, controls, and the ability to configure entire swathes or your infrastructure with a single configuration.
Keeping in line with our deployment philosophy, in case of transient failures that result in components being unable to communicate, clusters continue to operate in their current state — with the caveat of not being able to reach the segmented off sections of the ecosystem.
Data Plane
Istio uses an extended version of the Envoy proxy as the data plane. Envoy is a high-performance edge/middle/service proxy, designed to mediate all inbound and outbound traffic for all services in the service mesh. Envoy proxies are deployed as sidecars to applications and augment those applications with traffic management, security, and observability capabilities.
Deploying Envoy as a sidecar will automatically configure all inbound and outbound traffic to go through Envoy. This allows the augmentation of services to happen without requiring you to re-architect or rewrite your application.
Modern API GW, WAF, and other "edge" functionality
With Envoy as our consistent data plane, we can use it to deliver capabilities that were traditionally limited to the edge or DMZ anywhere in our application traffic platform. TSB combines a range of Envoy's features together into an easy-to-use package to enable API gateway features like token validation, rate limiting, and OpenAPI-spec based configuration. It also brings WAF capabilities to the sidecar, ingress gateways, and edge load balancers. And best of all, TSB allows you to write a single policy and apply it to traffic anywhere: between external clients and your services, across clusters or data centers in your network, or even between services running on the same clusters.
Extensions
The extension point of TSB in the data plane is WebAssembly. Envoy has several extension points, but normal Envoy extensions require rebuilding and linking the Envoy binary WebAssembly is a sandboxing technology that can be used to extend Envoy dynamically since Istio 1.6.
An overview of WebAssembly extension can be found in the Istio documentation. In TSB, a better support of WebAssembly extensions is provided via WASM extensions and Istio's WasmPlugin resource. It helps developers build and test Envoy extensions and integrate with TSB to help the deployment of extensions.
Local Control Planes
TSB uses Istio for the local control plane within each cluster, which means that you get the benefits of having isolated failure domains with multiple Istio instances, and easy, more standardized management from the TSB management plane.
As a user, you access and control them from the management plane, which means you have no direct interaction with the local control planes. What's more, you only need to push a single configuration to update them all.
The local control plane is responsible for:
- Smart local load balancing
- Enforcing zero-trust within the cluster
- Enforcing authentication and authorization at a local level
The control plane is that local point of access for TSB to push configurations, to mine data, and then make intelligent decisions based on what it's seeing within that cluster.
Global Control Plane
The Global Control Plane (XCP) is part of the management plane, and as a user, there's no direct access to the global control plane's APIs. The global control plane is responsible for:
- Service discovery between clusters
- Telemetry that is collected from the local control plane and data plane
- Disaster recovery and failover in the case of a gateway outage or cluster failure
- Authentication and Authorization for users and between applications
- Egress controls to determine what can leave the network.

Global Control Plane enables clusters to communicate with each other and advertise the services that are available.
Global Control Plane is comprised of two applications, XCP Central and XCP Edge. XCP Central is deployed in the TSB Management Plane and is responsible for configuration propagation to the XCP Edge applications. XCP Edge applications are deployed in each onboarded cluster, where the user applications run, for local translation of TSB configuration to Istio API.
Compared to other methods of building a mesh across many clusters using Istio — namely publishing Pod or VM IP address changes for every service for every cluster to all other Istio instances — the rate of change of the data we need to propagate is very low, the data itself is very small, and there's no n-squared communication across clusters needs to happen (which each Istio in each cluster syncing with all remote cluster endpoint updates). This means it's significantly easier to keep up to date and accurate, resulting in a simpler system overall. Simpler is always easier to run and more reliable. TSB's method of facilitating cross-silo communication results in a very robust and reliable runtime deployment.
Tetrate Service Bridge Management Plane
The TSB management plane is your primary access point to everything within your mesh-managed environment.
The management plane enables easy management of your environment by splitting up your infrastructure into workspaces, groups and services. With these logical groupings, TSB gives improved user experience for managing your environment.
Any changes that impact your mesh-managed environment are controlled from the management plane, including runtime actions like traffic management, service discovery, service-to-service communication, and ingress/egress controls, as well as administrative actions like managing user access (IAM), security controls, and audit.
Understanding the Management Plane
In the previous page on the Service Mesh Architecture we introduced the concepts of the data plane and control plane. Above we introduced the idea of failure domains, and why it means we want to deploy many instances of our local control plane. Having many of local control planes naturally means we need something to help make them act as a whole, so the global control plane checks out. But why add another layer over top in the management plane?
Unlike a control plane, who's primary job is to be available, low latency, and serve data plane configuration as quickly as possible (it changes at the speed of machines), a management plane's primary job is to facilitate users interacting with the system, and the workflows between them.
The management plane is the layer that binds the runtime system to the users and teams in your organization. It's what lets you administer a distributed system in a complex organization with many users and teams, with many different policies and interests, on the same physical infrastructure, safely. It takes an awesome set of technologies — Envoy, Istio, and SkyWalking — and binds them into a tool that can be used in enterprise to implement controls for regulatory requirements with confidence, maintain many unrelated teams on the same infrastructure without shared fate outages, and let teams as fast as they want knowing it'll be safe and secure.
We'll talk about what you can do with the Tetrate Service Bridge management plane in the rest of the concepts section, from empowering application developers to manage traffic to applying global policy and managing user access with TSB's IAM system to understanding your entire infrastructure in a single pane of glass. But at a glance, it lets you:
- Control traffic flow in one place no matter where the application or its dependencies are deployed
- Manage who can change what with an advanced permission system (keep application developers from changing security settings; keep the security team from causing app outages)
- Audit every change in the system
- Understand and control traffic flow in your system: internal traffic, ingress, and egress
- Manage control plane life cycles across your entire infrastructure
Detailed Data Flow
This detailed, under-the-covers view of Tetrate Service Bridge's components and data flow can help you understand the pieces that make up the runtime system and how data flow between them.
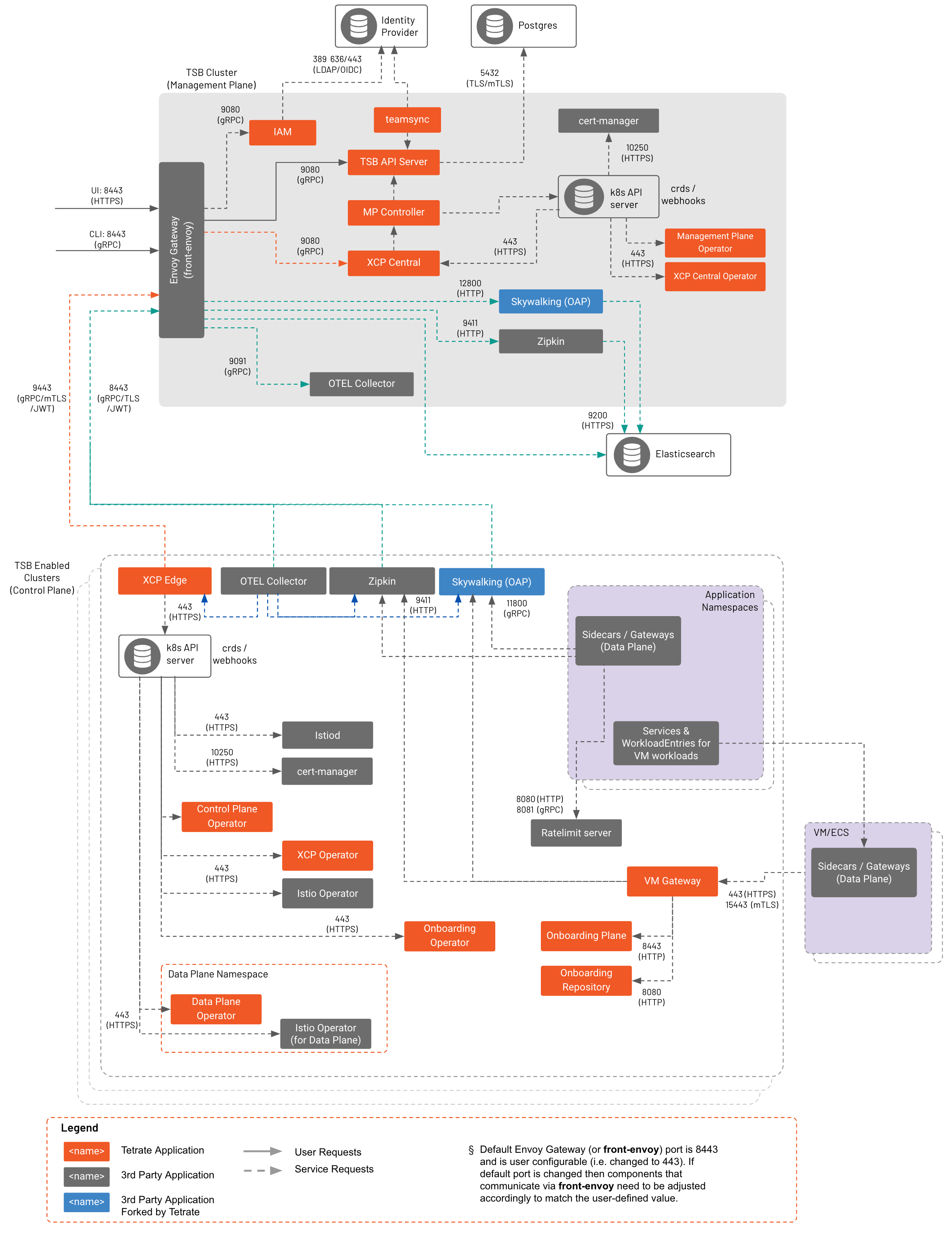
Detailed description of each component is available in TSB components. For complete list of ports used by each component, go to Component ports.