 Tetrate Service BridgeVersion: next
Tetrate Service BridgeVersion: nextUnderstanding HA and DR for the Tetrate Management Plane
An introduction to Management Plane architecture and HA strategies
The Tetrate Management Plane and distributed Control Plane architecture is designed for reliability:
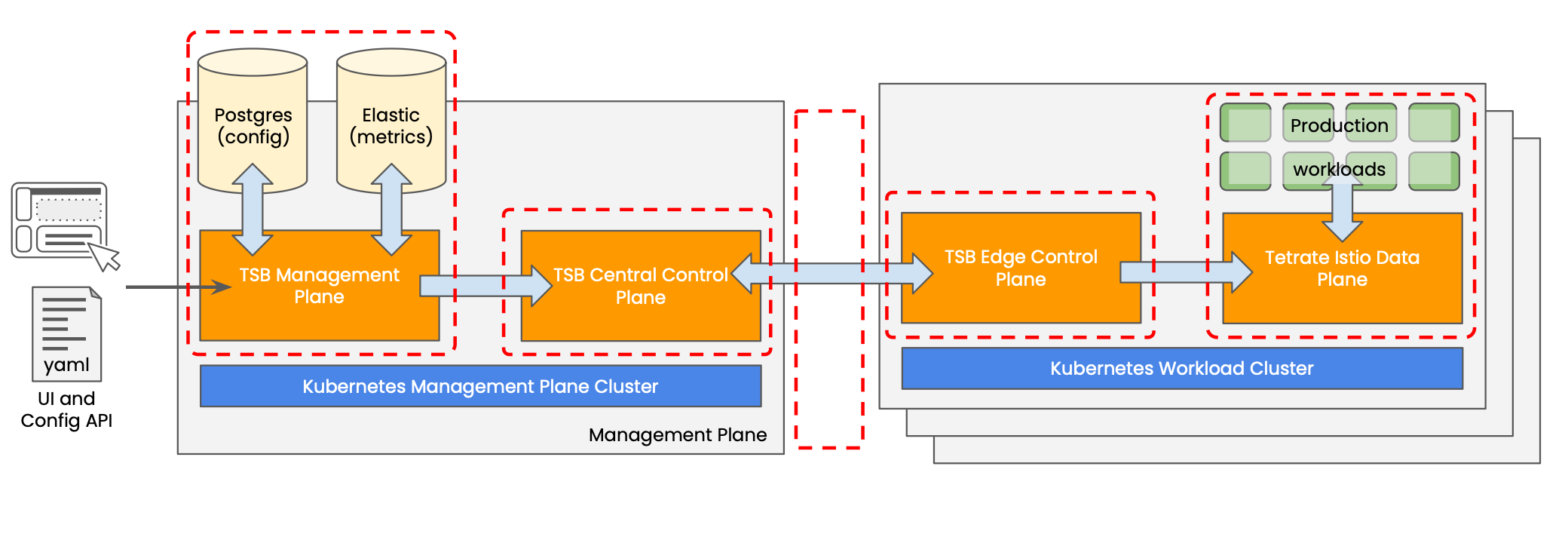 Tetrate Management Plane and Control Plane Failure Domains Tetrate Management Plane and Control Plane Failure Domains |
|---|
- Architecture is loosely coupled: being loosely coupled, the 'blast radius' of failures is limited.
- Stateless, auto-recovering components: Almost all components are stateless and automatically regain their configuration; the three exceptions are the Postgres DB (configuration and audit logs), the ElasticSearch DB (metrics), and the secrets in the K8s cluster
- Data plane is not dependent on the control plane: Failures in any management or control plane component do not affect the correct operation or security of applications and services running in the workload clusters.
Any failures in the Tetrate Management Plane, Central Control Plane or Edge Control Plane do not immediately affect your running applications. They will continue to operate as normal.
- Failures in a workload cluster are limited to that cluster only, and the cluster will reacquire its configuration automatically when it recovers
- If the management plane or central control plane becomes unavailable, then configuration changes and reconfigurations due to application failures cannot be processed
Refer to the Failure Scenarios description for a complete account of the failure events and their effects.
This design guide describes the configurations you can follow to backup and restore your management plane, and how to maintain a standby MP service and perform a failover if necessary.
Recommended Good practices: Workload and Dataplane
We recommend running workloads in a redundant, HA fashion. Capabilities such as Tetrate's Edge and East-West gateways, plus integration with GSLB solutions such as Amazon Route 53 provide high-availability for production workloads in the event of failure in Workload clusters for any reason.
Tetrate's solution does not rely on any of the multi-region DR configurations for the Istio dataplane. These are required when no higher-level control plane is in place, and they add significant complexity and additional failure scenarios. Tetrate's Control Plane architecture means that single istio-per-cluster deployments are entirely sufficient and provide better isolation in the event of a failure. Furthermore, smaller failure domains make progressive upgrades easier and less risky.
Recommended Good practices: Management Plane
The Tetrate Management Plane stores state in three different ways:
- Basic configuration, such as authentication keys, is stored in the
tsbnamespace in the Management Plane cluster. This configuration rarely changes after initial installation. It should be backed up when the management plane is first installed, and any time that basic changes are made. - Service configuration and configuration audit logs are stored in either TSB's embedded Postgres Database, or an external Postgres database. The external Postgres database is hosted by the user according to their own scaling, clustering and backup practices.
- Observability data (metrics, logs, traces) are stored in a remote ElasticSearch database. Observability data is generally not backed-up due to the volume and short-lived nature of the data, and because it is not critical to restore in the event of a failure
Refer to the Data and Telemetry Storage section to understand the limitations of using embedded Postgres and Elasticsearch in production.
To prepare for failure and recovery:
- Always maintain a backup of the Management Plane configuration so that you can reinstall a new Management Plane instance at any point
- Use an intermediate DNS address that you can easily modify, to point client clusters to a new Management Plane instance
You have two options to address high availability for the Tetrate Management Plane:
-
Option 1: Run a single, active Management Plane instance. In the event of an unrecoverable failure, deploy a new Management Plane instance using backups that you maintain
-
Option 2: Run a warm standby Management Plane instance. In the event of an unrecoverable failure, move control to the standby Management Plane instance
Option 1: Single Management Plane
Many Tetrate users operate a single Management Plane instance and rely on backups to restore a Management Plane in the event of a catastrophic, unrecoverable failure. Given that catastrophic failures are rare and do not affect running applications, and that the Management Plane can be quickly reinstalled and restored, this is generally a sufficient approach.
In the event of a Management Plane failure, you should first attempt to recover the Management Plane. If it is not possible to recover, you can deploy a new Management Plane instance and then:
- Restore a backup of the Basic configuration (into the TSB installation)
- Point the new Management Plane instance to the external Postgres database if it is still available. If not, deploy a new database and restore the configuration from a backup
- Point the new Management Plane instance to the existing ElasticSearch database if it is still available, or deploy a new database.
Make the new instance active by updating the DNS address that points to your Management Plane. The remote Workload clusters will connect to the new Management Plane.
The steps are described in detail in the Manual Recovery of the Management Plane documentation.
Option 2: Active-Standby Management Plane
In addition, it is possible to host a standby Management Plane instance which can quickly made 'active' in the event of a catastrophic, unrecoverable failure. This configuration is a little more complex, and you should always maintain separate backups so that you can deploy a new Management Plane instance in the event that failover is not possible.
When you operate a standby Management Plane, you have several options:
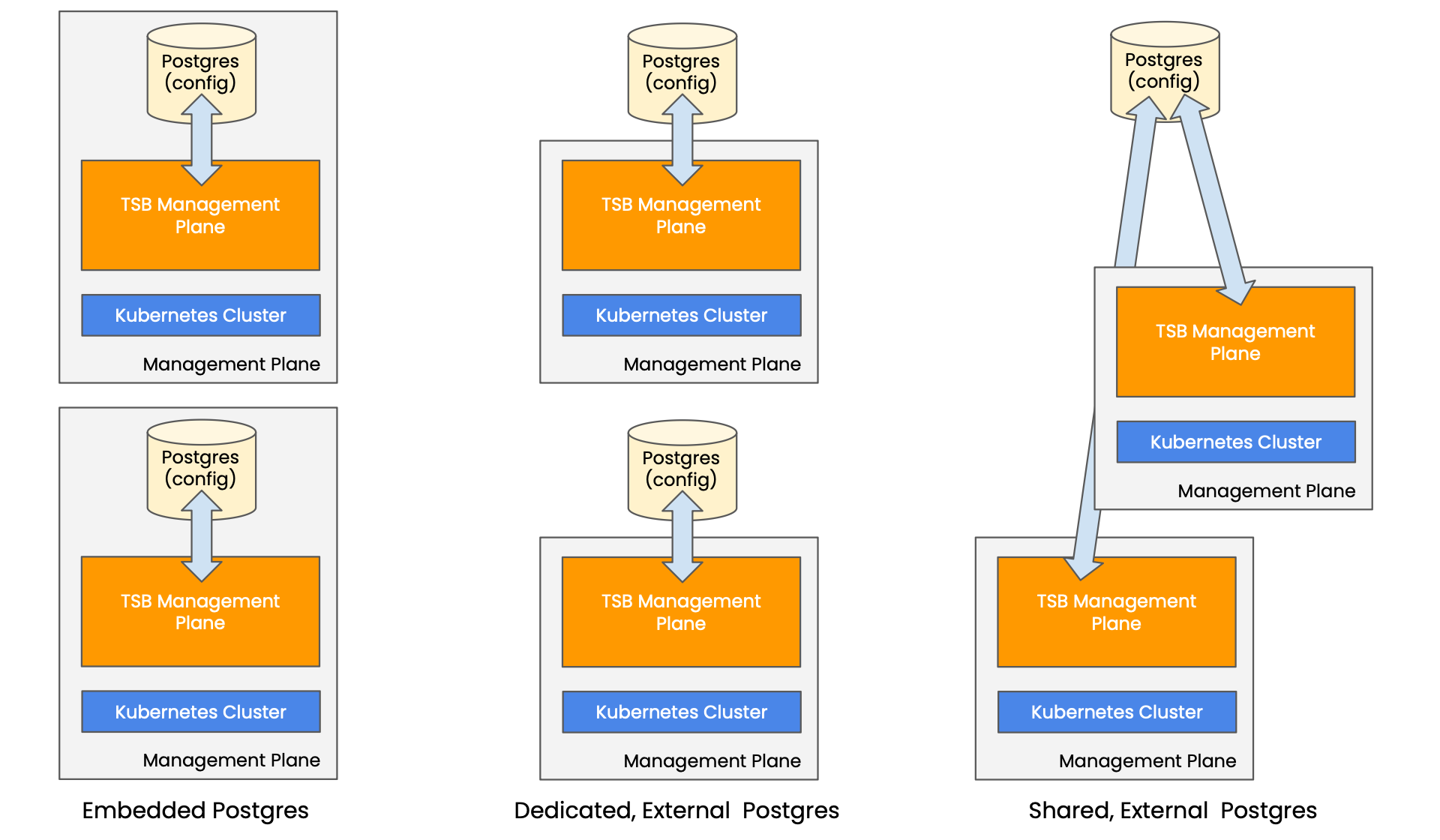 Tetrate Postgres - Embedded or External (dedicated or shared) Options Tetrate Postgres - Embedded or External (dedicated or shared) Options |
|---|
- Separate Databases: The Active and Standby instances each use a dedicated database (either embedded or external). You must actively synchronise the database contents from the Active instance to the Standby instance, either by regular backup-and-restore operations or by using a replication solution. This approach is more complex to operate, but removes a single point of failure
- Shared Database: If you are using an external Postgres database, you can point both the Active and Standby instances at a single, shared Postgres database. This removes the need to synchronize configuration from one active) database to a second (standby) database, and you should take regular backups in the event that the shared database fails
In the event of a Management Plane failure, you should first attempt to recover the Management Plane. If it is not possible to recover, you can fail over to the standby Management Plane instance:
- Verify that the Standby instance is running and has current (or recent) configuration
- Start the control plane services on the standby instance and terminate them (if possible) on the failed active instance
Make the standby instance active by updating the DNS address that points to your Management Plane. The remote Workload clusters will connect to the new Management Plane. Delete the old, active instance on the basis that it was not recoverable, so cannot be reused.
The steps are described in detail in the Active-Standby Management Plane documentation.
Always maintain a separate backup of the basic and service configuration, so that you can deploy a new Management Plane instance in the event that the failover process cannot succeed.