 Tetrate Service ExpressVersion: Latest
Tetrate Service ExpressVersion: LatestTetrate Service Express Capabilities
Tetrate Service Express uses Istio to secure, manage and observe traffic within and between EKS clusters and off-cluster workloads.
A Zero-Trust Security Posture
TSE-managed policies apply a Deny-All-by-default security posture, mTLS everywhere, and Identity-based Access Control
TSE's security model allows for flexible configuration of runtime security policies: encryption in transit (mTLS) and end-user authentication (JWT based authentication).
TSE uses service identities rather than L4 identities, providing great control in a dynamic environment. Service identity is powered by Istio and SPIFFE, giving every workload a verifiable identity for authentication and authorization at runtime. The SPIFFE identities are issued by Istio and rotated frequently at runtime, and form the basis for the identities for authentication between workloads and for encryption in transit.
TSE's access control policies are based on TSE's 'Workspace' concept. This gives a convenient, higher-level abstraction that is better aligned with the way that applications are deployed and is separate from the underlying network and Kubernetes deployment choices. By starting with a 'deny-all' posture, and incrementally opening up access, you can accurately limit which services can speak to each other, reduce the potential for lateral spread for attacks perpetrated against network-based systems that a service mesh manages.
Istio rotates certificates aggressively (as frequently as hourly), so attacks are also limited in time. An attacker has to persist an attack or re-steal credentials frequently, greatly increasing difficulty.
Finally, and maybe most important of all, by using service identities for access control policies, TSE decouples those policies from the underlying network and infrastructure. TSE's security policies are portable across environments (cloud, Kubernetes, on-prem, vm).
Ingress Networking
TSE deploys and manages Ingress and Edge Gateways, which provide high-availability and perimeter control for external requests
As traffic enters through your TSE environment, it passes through one or more TSE-managed gateways to reach the final service instance it needs.
First, the traffic may pass through an Edge ("Tier 1") Gateway. This is a shared multi-tenant gateway responsible for cross-cluster load balancing. The Edge Gateway proxies traffic to the destination cluster, which is typically fronted by a lightweight AWS load balancer (NLB or equivalent), or may proxy traffic directly to the target workload (common for VM workloads). Edge Gateways are optional, and Route 53 or other GSLB / edge load balancers may be used instead.
When the traffic reaches a cluster, it is typically load-balanced by an AWS load balancer to one or more TSE-managed Ingress Gateways in the cluster. Ingress Gateways are owned by a Workspace, and may be shared between multiple Workspace applications, or dedicated to a specific application. This means that the Workspace's owner remains in control of how traffic is admitted to their applications, and allows the mesh configuration to be segmented and isolated efficiently and safely.
TSE Ingress Gateways are instantiated using instances of Envoy, which is lightweight and easily scalable. Multiple Ingress Gateways allow for isolation and control of traffic, reducing the risks of outages or overlapping configuration. It's also possible to consolidate individual Ingress instances into a smaller set of shared Ingress Gateways, leaving a few dedicated gateways for critical applications. TSE lets you make this decision in a smooth gradient, running one gateway or thousands.
Intelligent Traffic Routing
TSE routes traffic into and through your cluster, with the goal of achieving high availability and latency minimization
For TSE to manage application traffic, it needs to know where all the service instances are, and whether they are currently available. TSE synchronizes this information from the TSE Control Planes in each cluster. With this, TSE can configure each Istio mesh to keep traffic as local as possible, including in the same availability zone, for multi-availability zone clusters.
TSE uses Envoy's capabilities to route traffic per-request, not per connection. This gives control over how your application communicates: keeping all requests sticky to a specific backend instance, applying canary routing on a portion based on header or percentage to a new version, sending requests to any available backend no matter where it runs.
Multi-Cluster Routing
TSE scales across clusters, and provides a routing layer that enables clients to access services whether they be located locally or in a remote cluster
Services in a TSE-managed environment are identified by an address (hostname, DNS name, short name or even IP address), defined by the service owner when the service is published.
TSE makes cross-cluster (cross-silo) networking simple. It does so in an efficient, dynamic and scalable manner, without the N-squared problem of pushing every clusters' entire runtime state to every clusters' controlplane. TSE publishes just the entry points for each cluster, plus a directory of the services available within each cluster to each Istio control plane. Clients in the mesh (or external clients via an Edge Gateway) can access a service by hostname without knowing any details about where the service is deployed.
Combined with the intelligent traffic routing, the TSE-managed mesh routes traffic to local instances of a service if they're available, or out into other clusters that expose the service if it's not local (or if it fails locally). If the application is exposed with a gateway, TSE will still route to the local instance directly, avoiding an inefficient "hairpin" routing scenario.
Cross-Cluster, Zone and Region Failover
Cross-cluster failover allows for fine-grained and efficient scaling and redundancy for any internal service
The principle of "Keeping It Local" directs the design to a set of uncoupled, redundant silos. This results in inefficient use of resources, and makes failovers a major event.
Generally, a more fine-grained approach to failover is preferable, where the application finds the nearest healthy instance of a service it requires. The application uses the local instance in favor of a remote one unless the local instance fails. This is a more efficient approach than failing over an entire silo. To facilitate this, many systems "hairpin" internal traffic, routing it though local or edge load balancers and then back into the working cluster, even if the desired service instance is nearby.
If a service fails locally, or if a service needs to communicate with a remote dependency, the local TSE-managed mesh directs traffic to the nearest remote cluster, without needing to know the internal state of that cluster.
Global Observability
Observe traffic, logs, traces and events across all clusters, from a single point of control
TSE makes understanding the entire world simple by consolidating the metrics from every cluster enrolled in the service mesh into a single view. This means you can view application communication and topologies across clusters, availability zones, and regions, in a consistent fashion and without requiring any application modifications.
TSE exposes detailed operational metrics (RED - Rate, Error, Duration), centralizes the logging from every application in the mesh, gathers distributed traces for troubleshooting and performance analysis.
Service Metrics
TSE also provides a service-centric view, giving a single view of an application's health regardless of where it is deployed or what versions exist:
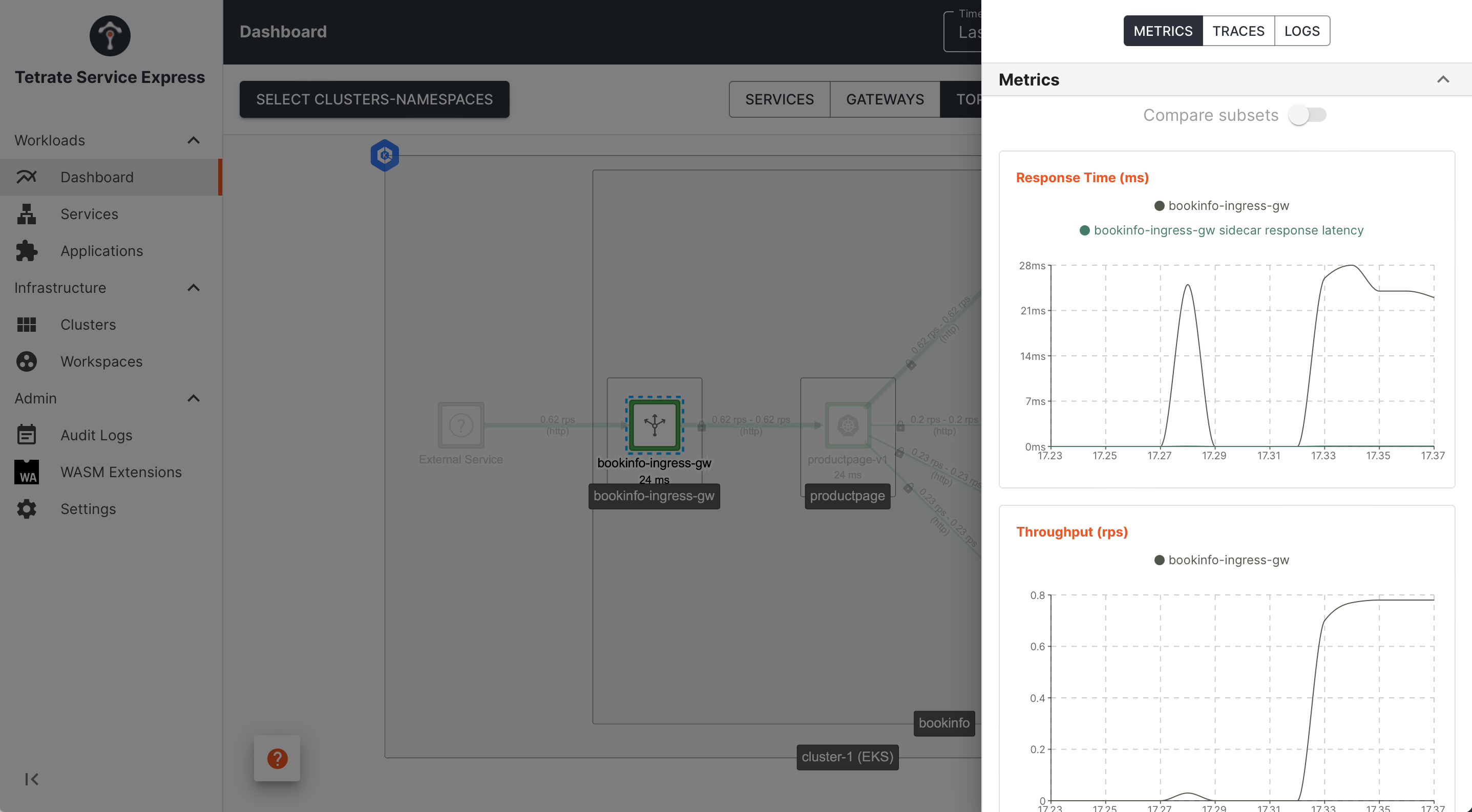 TSE Dashboard UI: service instance metrics TSE Dashboard UI: service instance metrics |
|---|
Traces provide a detailed call graph to help understand performance and error cases:
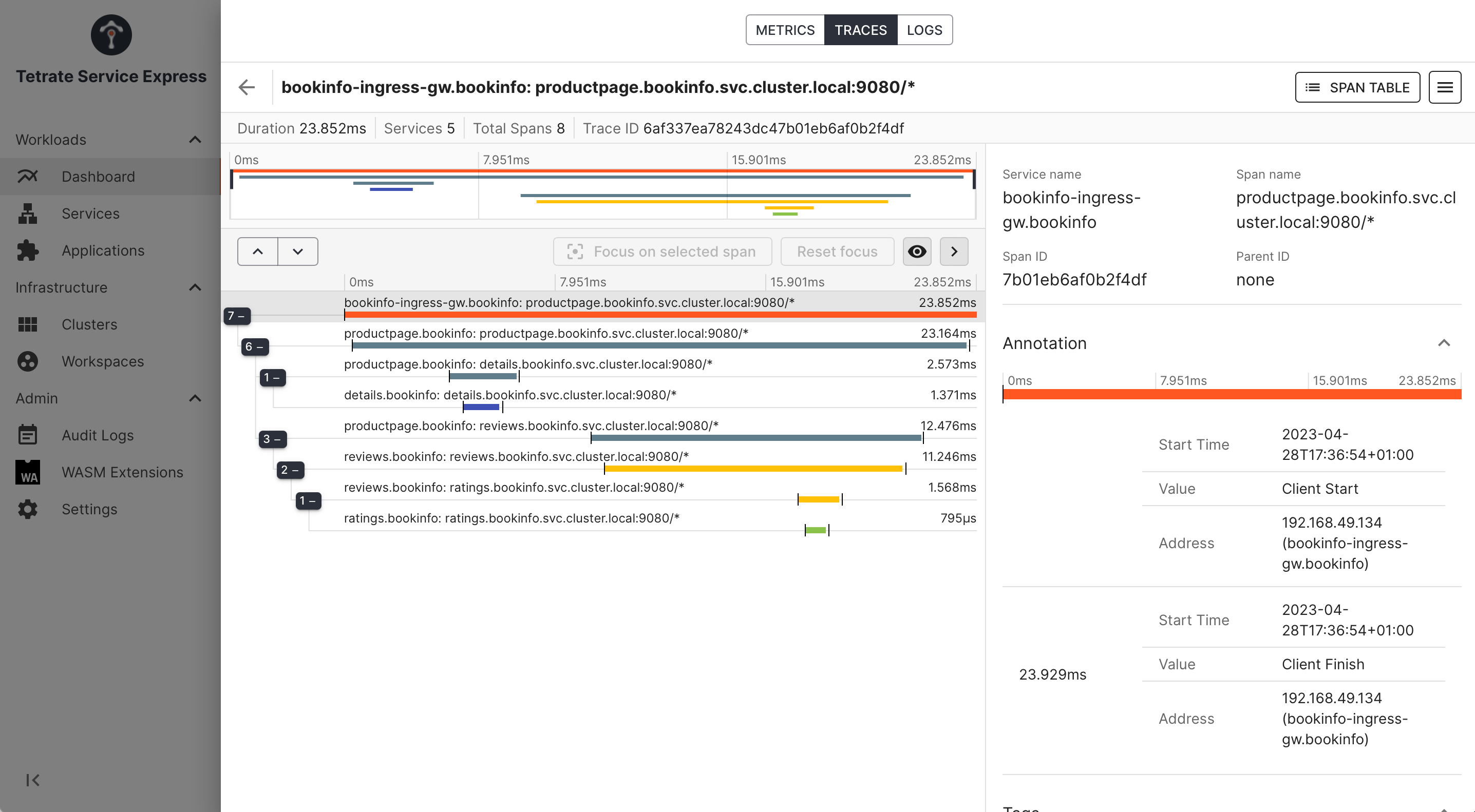 _TSE Dashboard UI: inspecting a trace _ _TSE Dashboard UI: inspecting a trace _ |
|---|
Deep-dive into metrics for individual services:
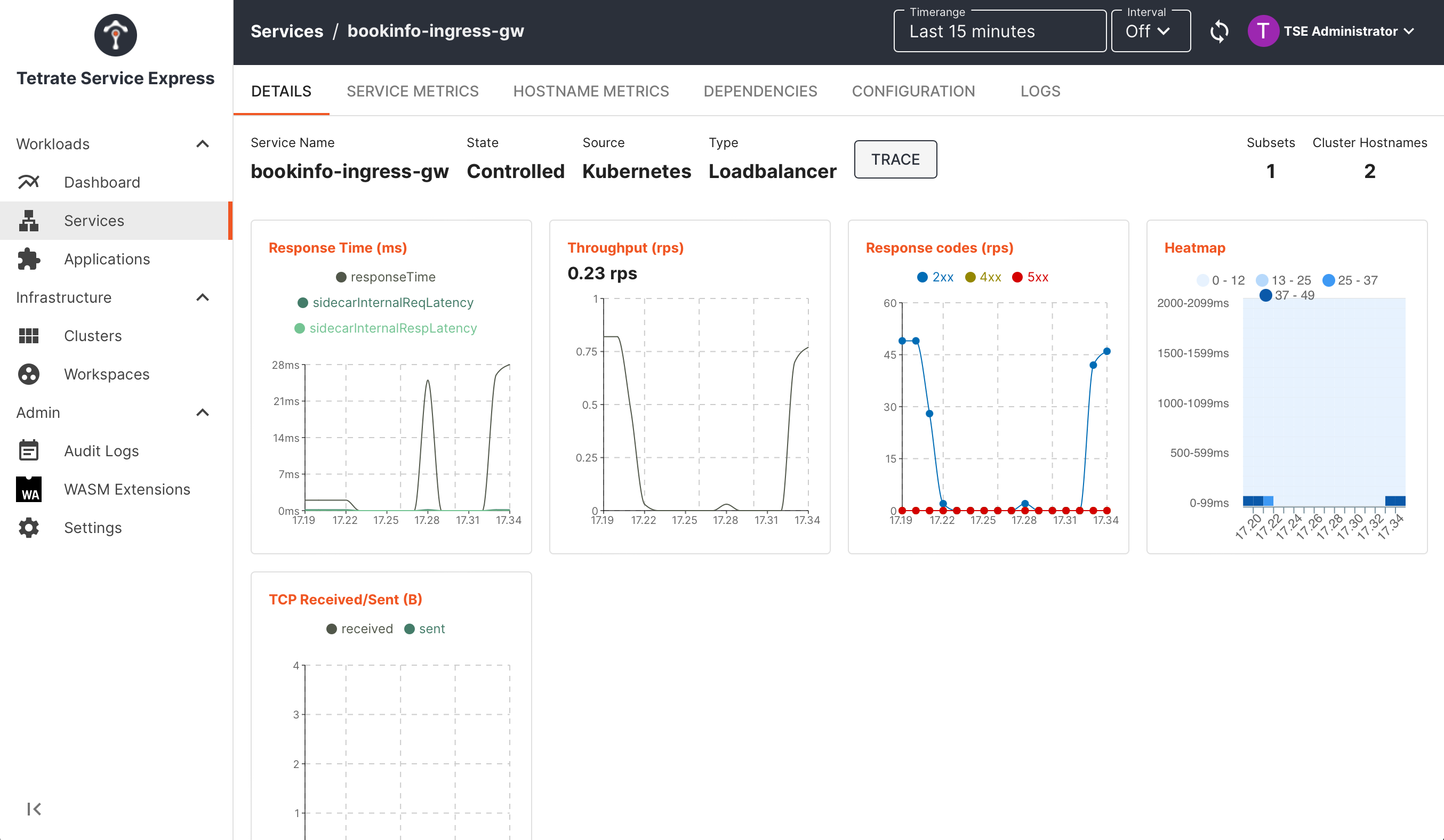 TSE Service UI: inspecting metrics for a service TSE Service UI: inspecting metrics for a service |
|---|
TSE and GIT
Automate the deployment and management of applications with TSE's GitOps integrations
With GitOps integrations, your CI/CD pipeline can push configuration changes to TSE while maintaining the single source of truth in Git. All TSB configuration objects can be constructed as Kubernetes Custom Resources, and so can be pushed to the platform in the same way that application configuration is pushed. You can bundle both Application and TSE configuration together, and deploy together, for example, within the same Helm chart.
Once TSE resources are applied to a local cluster, they are automatically reconciled and forwarded to the TSE management plane.