 Tetrate Service BridgeVersion: 1.5.x
Tetrate Service BridgeVersion: 1.5.xService Mesh Introduction
The Service Mesh architecture is being widely adopted today, and the team at Tetrate is made up of some of the earliest engineers building the technologies that enable the architecture. In this page we'll introduce the architecture and terminology, outline the capabilities and features, and discuss Istio - the leading mesh implementation and the service mesh that powers Tetrate Service Bridge.
What is a service mesh?
Service mesh is an infrastructure layer that sits between the components of an application and the network via a proxy. These components are often microservices, but any workload from serverless containers to traditional n-tier applications in VMs or on bare metal can participate in the mesh. Rather than each component communicating directly with each other over the network, proxies intercept that communication.
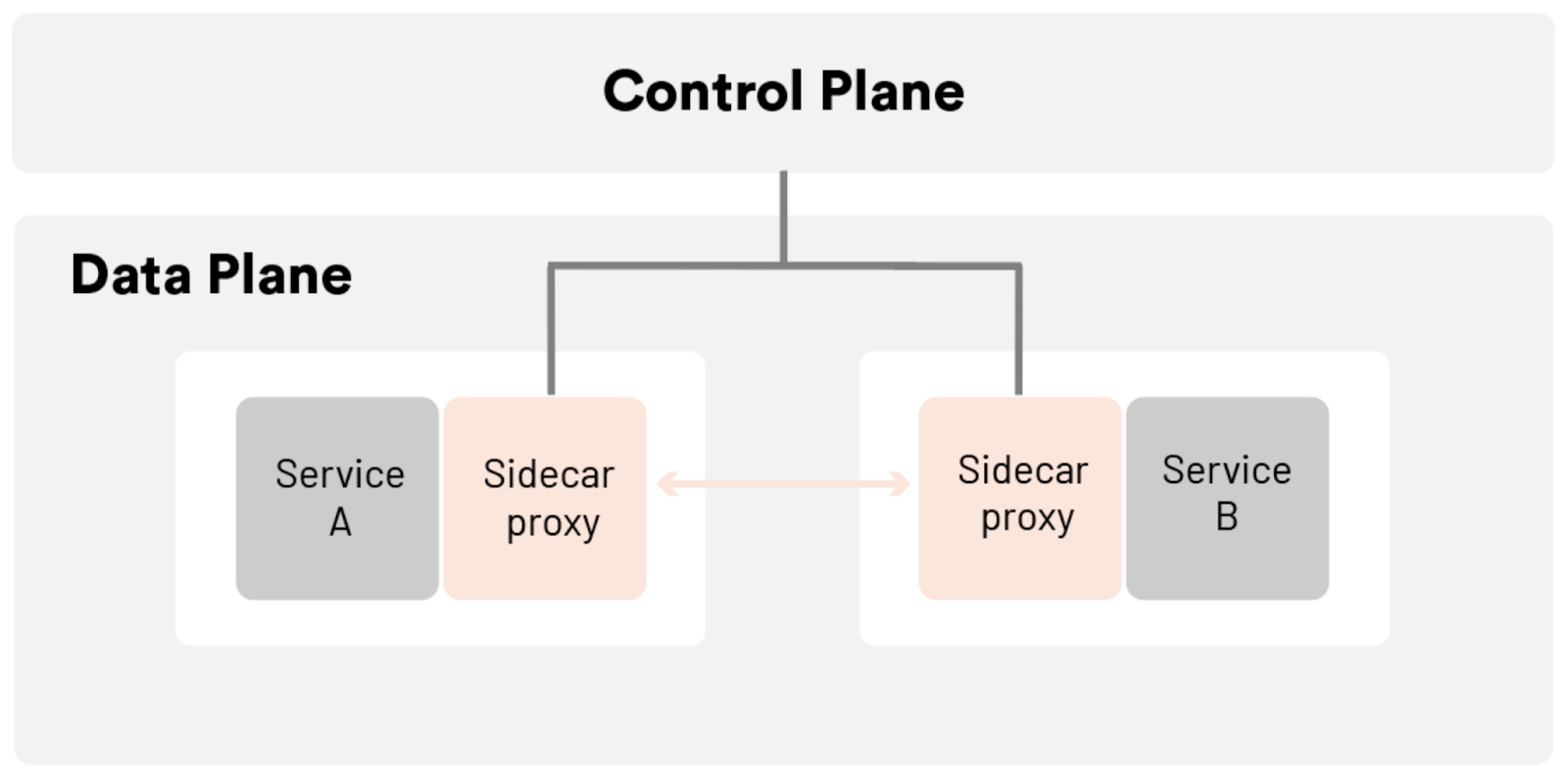
The Data Plane
These proxies -– which we call "sidecar proxies" because an instance of the proxy is deployed beside (sidecar to) each application instance -– are the data plane of our service mesh: they handle the bits-and-bytes of application traffic at runtime. In Tetrate Service Bridge, Envoy is used as the data plane implementation. It provides a ton of capabilities for implementing security and traffic policy as well as producing telemetry about the service it's deployed next too. Those capabilities include:
- Service discovery
- Resiliency: retries, outlier detection, circuit breaking, timeouts, etc.
- Client-side load balancing
- Fine-grained traffic control at L7 (not L4!): route by headers, destination or source, etc.
- Security policy on each request, rather than once per connection
- Authentication, rate limiting, arbitrary policy based on L7 metadata
- Strong (L7) workload identity
- Service-to-service authorization
- Metrics, logs, and tracing
All of these capabilities are available to some degree or other in frameworks and libraries today––for example, Hystrix, Spring Boot, Pivotal Cloud Foundry (PCF). However, by pulling these capabilities out of the application and into a the sidecar proxy, we can introduce a control plane to drive the behavior of our data plane and start to unlock many other benefits.
The idea of a "sidecar" didn't originate with the service mesh, though the service mesh is the first place many people encounter the idea directly. Sidecars tend to pop up when we have a crosscutting set of concerns. Some of the earliest "sidecars" in wide deployment were for log and telemetry collection - often deployed as daemons on your application VMs.
The idea of a sidecar is powerful for addressing horizontals - cross-cutting concerns - and deploying the pattern for controlling network traffic gives us a huge amount of leverage to offload concerns from applications into the platform. Once they're a platform concern they can be solved once, holistically, for the entire organization and not piecemeal by multiple parts of the organization.
The Control Plane
The control plane is responsible for configuring the data plane proxies at runtime. As declarative configuration is pushed to the control plane, it transforms those intents into concrete configuration for Envoy at runtime. In effect, the control plane weaves a bunch of individual Envoy proxies into a coherent mesh.
With a sidecar proxy beside every application instance and a control plane to configure those sidecars dynamically, we get centralized control with distributed enforcement that's not possible with the variety of frameworks and libraries littering the landscape today. This service mesh gives organizations with many applications, written in many languages and deployed across many different environments the benefits of:
- centralized visibility and control
- consistency across the entire fleet
- ease of change through policy and configuration implemented as code
- a lifecycle for these capabilities separate from any application lifecycle (which means you don't have to upgrade and redeploy an application to apply, for example, mTLS between components)
Tetrate Service Bridge uses Istio as its control plane to configure Envoys at runtime.
Where did the Service Mesh come from?
The service mesh architecture was concurrently created at a few different companies in the early 2010's as a natural outgrowth of challenges they faced adopting a service oriented architecture.
The origins of the service mesh at Google go back to challenges they faced transforming their internal application architecture from a centralized API gateway to decentralized microservices on a flat network. Several of the earliest Tetrands worked on the teams trying to tackle these challenges - throughout we'll talk about the problems we experienced alongside our coworkers and team members, and some of the lessons we learned.
The centralized gateway presented multiple challenges: from locality to cache coherency and increased overhead from extra hops. Two of the top challenges were cost accounting and shared fate outages. It was impossible for the team running the API gateway to perform cost attribution to individual teams using the gateway - making it hard to control costs and challenging to do capacity planning - as well as being a common root cause for outages affecting business continuity.
This poor fit between a central API gateway and a decentralized service architecture prompted the development of a proto-service mesh, where communication from users to services, as well as communication from services to other services was handled by sidecar proxies talking directly to each other instead of through a central API gateway.
The benefits of implementing service mesh at Google were striking. The team was able to easily do cost accounting, and shared fate outages due to individual team's misconfigurations were essentially eliminated. As the team, and the organization, grew more confident with the mesh, we started to see other benefits we didn't originally expect: it was an incredible tool for implementing cross-cutting features for the entire platform. For example, before the service mesh, an effort to add three IAM methods to all GCP APIs took 40 teams, each contributing around two engineers, more than six months to implement - it was an organizationally scarring experience. After the mesh was in place, a similar global API update to add policy checks to every resource took only two engineers one quarter to implement.
Shortly after the service mesh experience at Google, we started Istio to bring it to the world. Listening to Istio's earliest users, we heard a common set of challenges that the mesh uniquely addresses: not just shared fate outages or cost attribution, but difficulty enabling developers to build features for users more quickly while the organization grapples with the transition imposed by modernization and a move-to-cloud. We started Tetrate to build solutions for enterprises grappling with these challenges.
API Gateways and the Service Mesh
The service mesh's roots in Google started as a distributed API gateway; it was only later we learned to use it for other cross-cutting concerns. Three trends across industry today force us to believe we'll come full circle to API gateway-via-mesh in typical service mesh deployments:
-
An important implication of adopting a microservice architecture is that the amount of internal traffic ("east-west traffic") in your system dwarfs the amount of external traffic coming in or going out ("north-south traffic"). The rule of thumb is that you can expect around two orders of magnitude more traffic internally than externally. This may not be obvious until you consider the set of cross-cutting functionality you need to build to facilitate a microservice deployment: metrics, log, and tracing; abuse detection; authentication and authorization at each hop; service discovery; health checking; and so on.
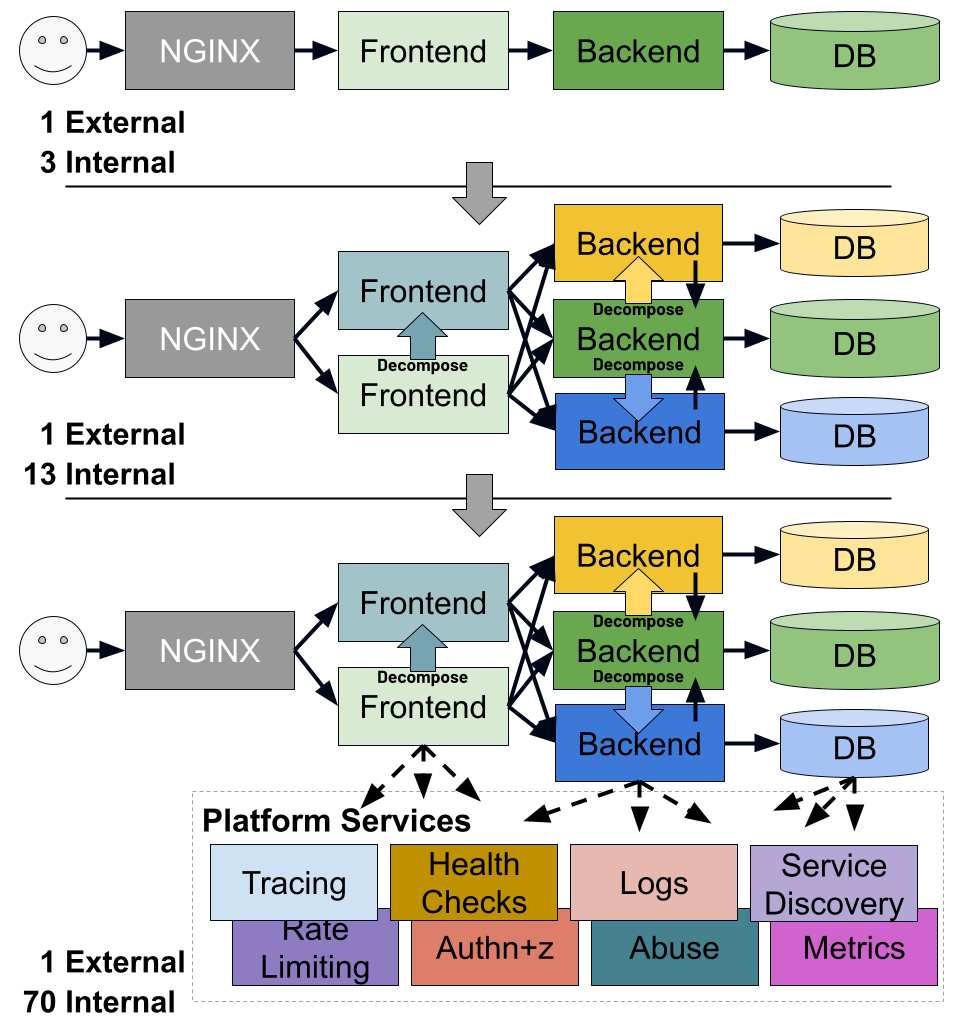
-
The move towards zero trust as the best-practice security architecture means that policy that you used to apply only to external traffic (at your network edge or the "DMZ") really needs to be applied everywhere. This is in part dictated by the security model (that assumes an attack could be anywhere in the network) but also by the point above: as the volume of traffic grows, external and internal traffic starts to look less and less different from the perspective of a developer building and operating an application. Capabilities like token validation, rate limiting, and WAF-style protections are needed for all traffic, not just external traffic.
-
For the first time we have a flexible, software based data plane that we can use to handle L4 and L7 traffic - Envoy. This lets us deploy a consistent set of capabilities everywhere across our infrastructure, then choose where they're enabled with configuration. This means we can start to write consistent policy for all traffic and apply it both at the edge to external traffic as well as in the mesh for internal traffic.
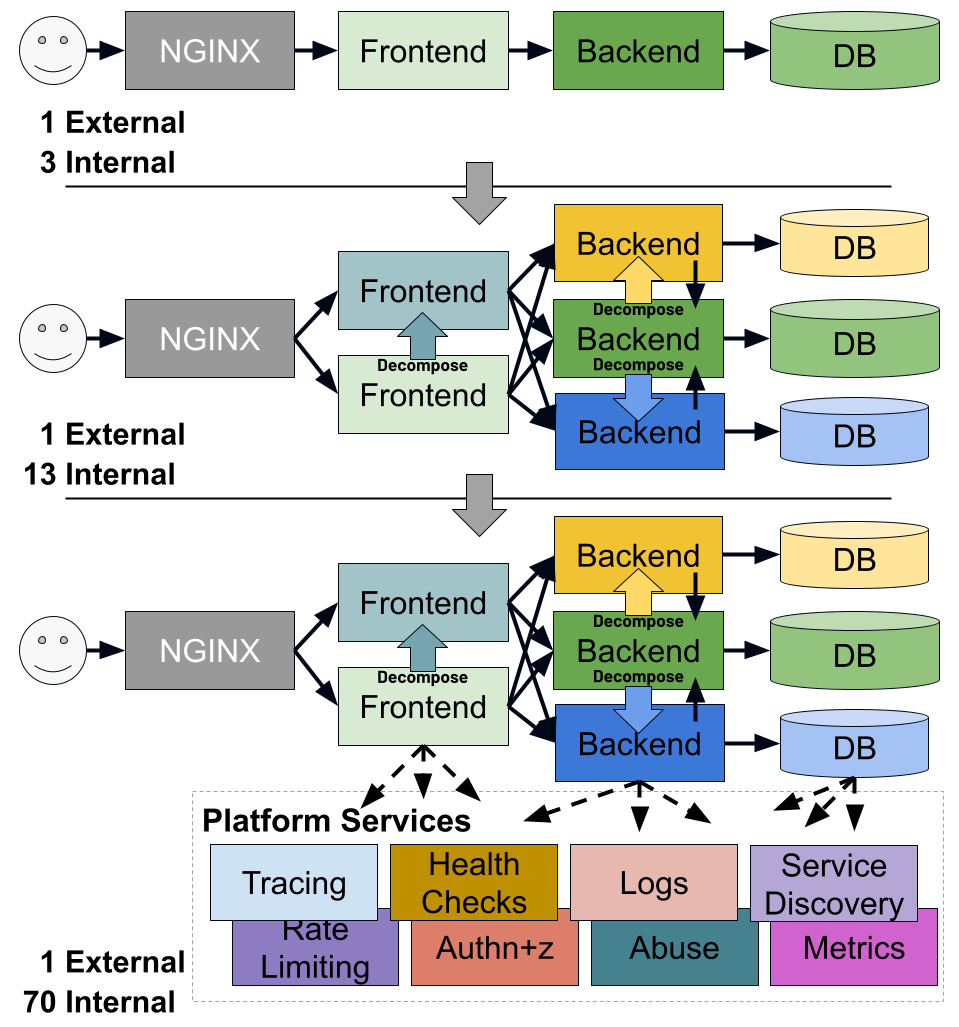
As a result, we think it's inevitable: the API Gateway will simply become capabilities of an application traffic platform, available everywhere in the platform. This trend won't stop at API gateway functionality either. We'll see many capabilities we traditionally think of as "edge" or "DMZ" appliances - like WAF - become capabilities of the application traffic platform.
Istio: the leading mesh implementation
"A service mesh is the right architecture for the enforcement of authorization policies since the components involved are moved out of the application and executed in a space where they can form a security kernel that can be vetted"
- National Institute of Standards and Technology (NIST), SP 800-204B
The mesh is the security kernel for microservices-based applications. So, the choice of service mesh implementation has a direct impact on application and information security. The level of intensity around development, bug fixes, and security patches should match the level of trust you expect to place in the mesh as your application security kernel.
Istio is the most widely used (CNCF, 2020) and robustly supported service mesh with a history of prompt CVE patches, paid security audits, and currently active bug bounties. It serves as the reference implementation for NIST's microservices security standards (NIST, SP 800-204A; NIST, SP 800-204B). And, Istio is the only service mesh with an ecosystem that enjoys both groundswell as well as support from multiple institutions large and small.
Istio is also evolving in tandem with the Kubernetes ecosystem to offer an ever more seamless experience. The new 2.x Kubernetes networking API now uses the Istio networking API. And, as Kubernetes projects like Knative expand [the Kubernetes ecosystem], standardization around Istio promises to make service mesh practices seamless across environments and deployment patterns.
Finally, the team at Tetrate was created by some of the earliest members of the Istio team at Google - we're intimately familiar with it and help implement and guide the project.
Given that, there was no choice but Istio to be the mesh that powered the capabilities we needed to deliver with Tetrate Service Bridge. Read the next section to learn about TSB and how it leverages Istio to weave your entire infrastructure into a single mesh.