 Tetrate Service ExpressVersion: Latest
Tetrate Service ExpressVersion: LatestAn Introduction to GitOps
Principles of GitOps
GitOps is a practice that uses Git repositories as a source of truth for application and system state. Changes to the state are performed through Pull Request (PR) and an approval workflow, and are then applied to the system by a CD process:
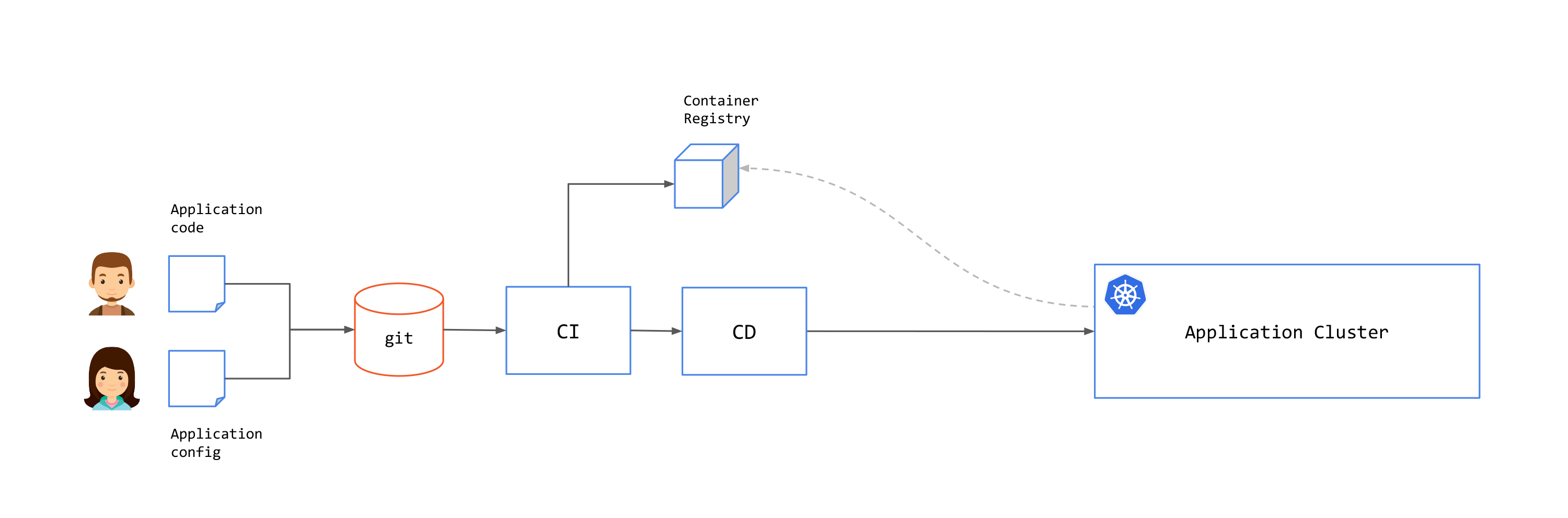
There are three core practices in GitOps:
- Infrastructure-as-Code: This describes the practice of keeping all infrastructure and application configurations stored as code in Git.
- Using Pull Requests for Changes: Changes are proposed on a branch, and a PR is made to merge the changes into the main branch. Using PRs allows for collaboration between the various teams responsible for applications, services, platform and security.
- CI (Continuous Integration) and CD (Continuous Deployment) Automation: Ideally, no manual changes are made to a GitOps-managed environment. Instead, CI and CD serve as a reconciliation loop. Each time a change is made, the automation tool compares the state of the environment to the source of truth defined in the Git repository.
GitOps Benefits
There are several benefits that you can get by using GitOps practices:
- Revisions with history: Every change is stored in Git, so it is easy to discover what changes have been made. Typically the change can be traced back to a specific incident or change request.
- Ownership: Changes are tracked in the Git history, so it is possible to find out who owns the relevant files (in this case mostly the manifest/YAML files). You can then quickly deduce ownership of related resources.
- Immutability: Any build or deployment is reproducible and immutable.
- Deterministic: The GitOps operator component periodically reconciles the runtime state with the desired state in Git, meaning that manual changes are quickly backed out and the configuration is fully determined by a single source of truth.
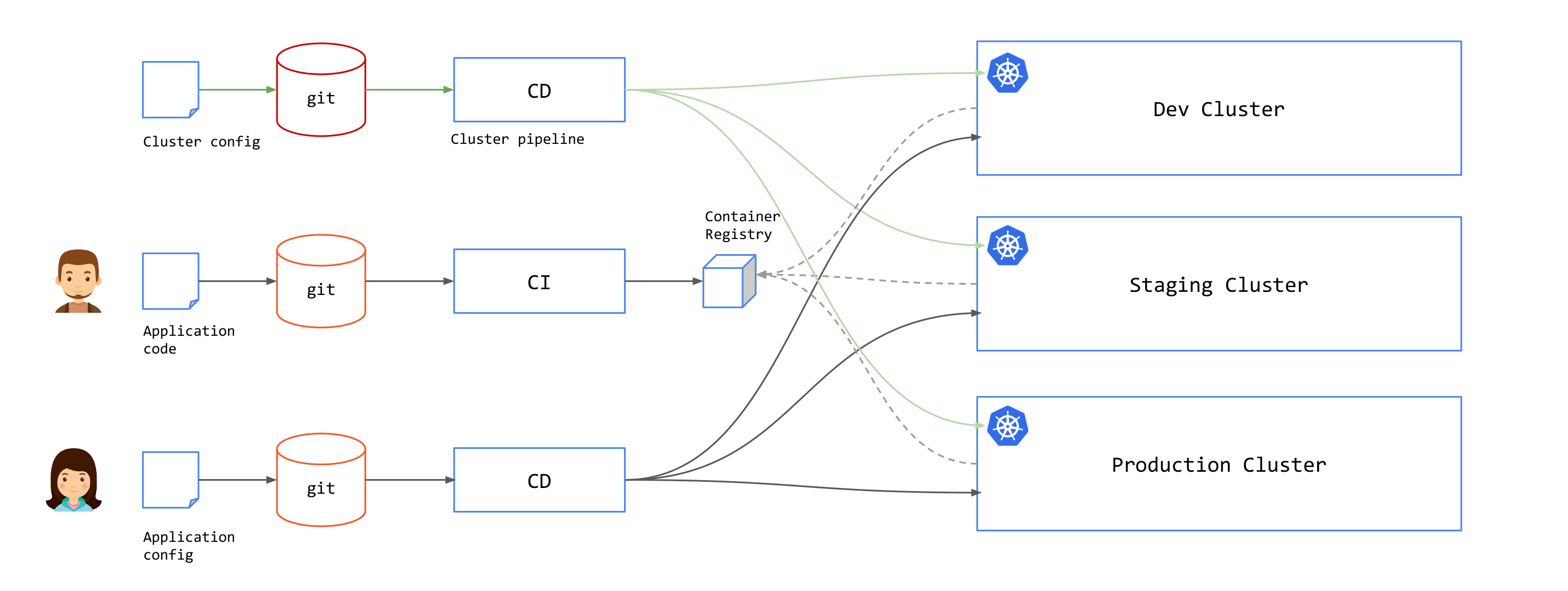
Separating Build (CI) and Deployment (CD)
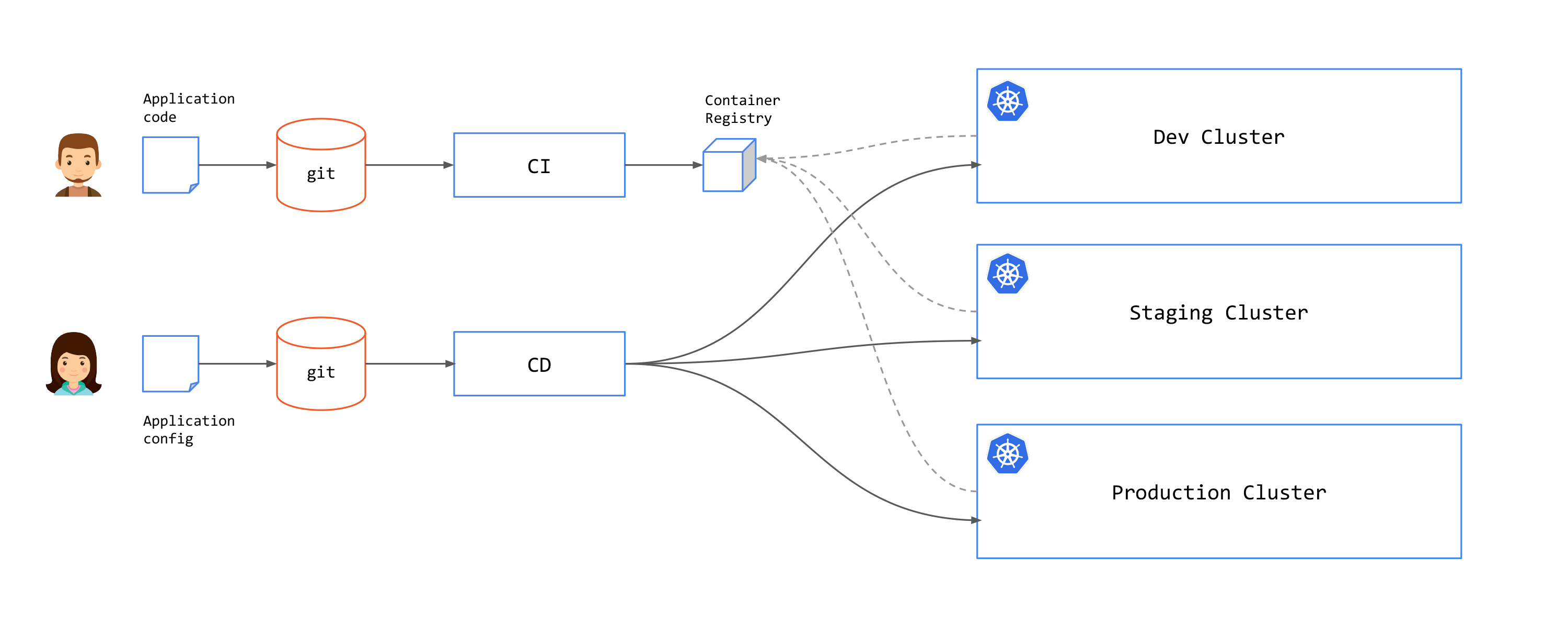
While you can have a single pipeline for both application code and configuration, you might want to separate the two. This would create two pipelines - an Application Owner pipeline to build artifacts for deployment (the CI pipeline), and a separate Operator pipeline to deploy these artifacts into production (the CD pipeline). This brings the following benefits:
- Separation of Concerns: Application developers commit code and create releases, which can be done in the CI. Application operators deploy artifacts to the clusters, which can be done in the CD
- Multiple Deployments: A single application build (CI) can be deployed to multiple environments (CD), without having to run the CI multiple times.
- Repeated Deployments: Recreating a deployment should not require a new build. Artifacts can deployed with CD without having to repeat the CI process.
You can connect CI with CD by using a reconciliation loop that will check for new artifact releases and create PR to the application configuration repository to update the application image tag.
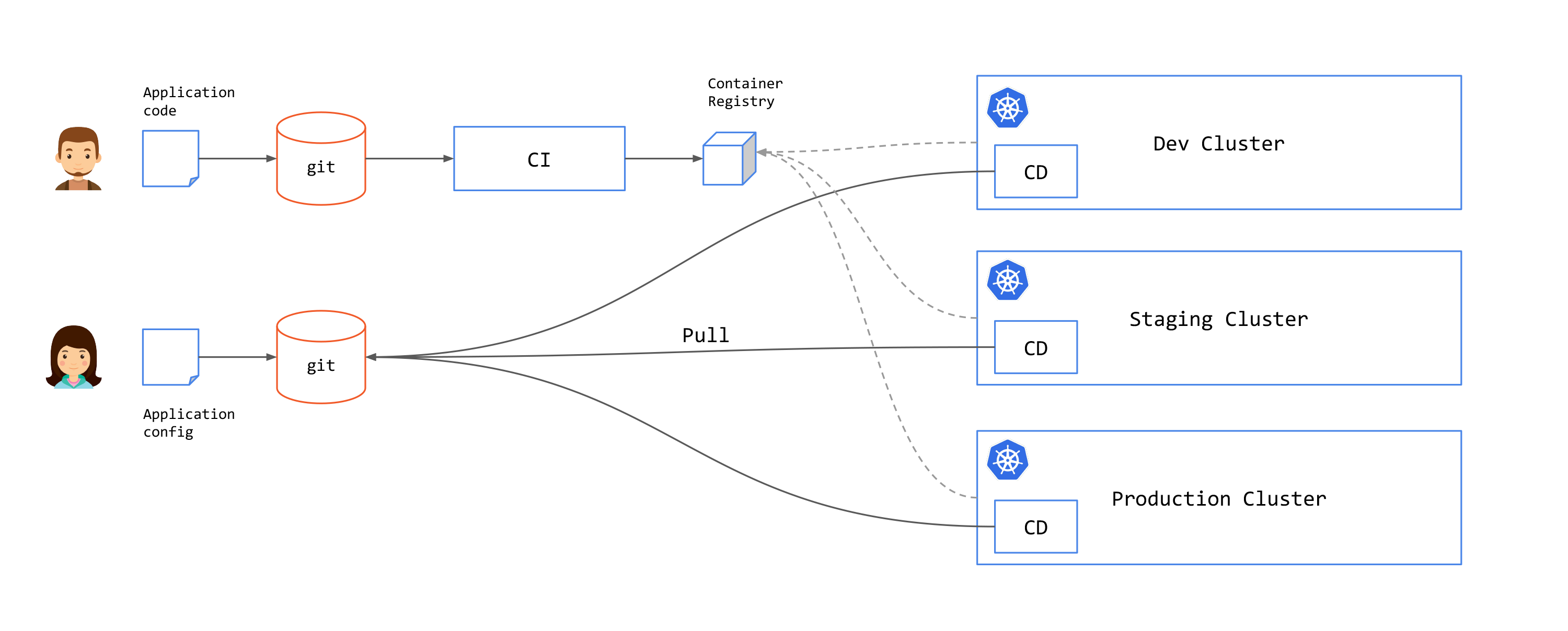
Push and Pull approaches for GitOps implementations
There are two approaches for GitOps: Push and Pull.
In the push approach, once a commit has been made on a git repository or a CI pipeline was executed successfully, an external system (a CD pipeline) is triggered to deploy the artifacts to the cluster. In this approach, the pipeline system requires the relevant permissions to write to the cluster.
Example of push solutions include Github actions, Azure Pipelines, GitlabCI, and CircleCI.
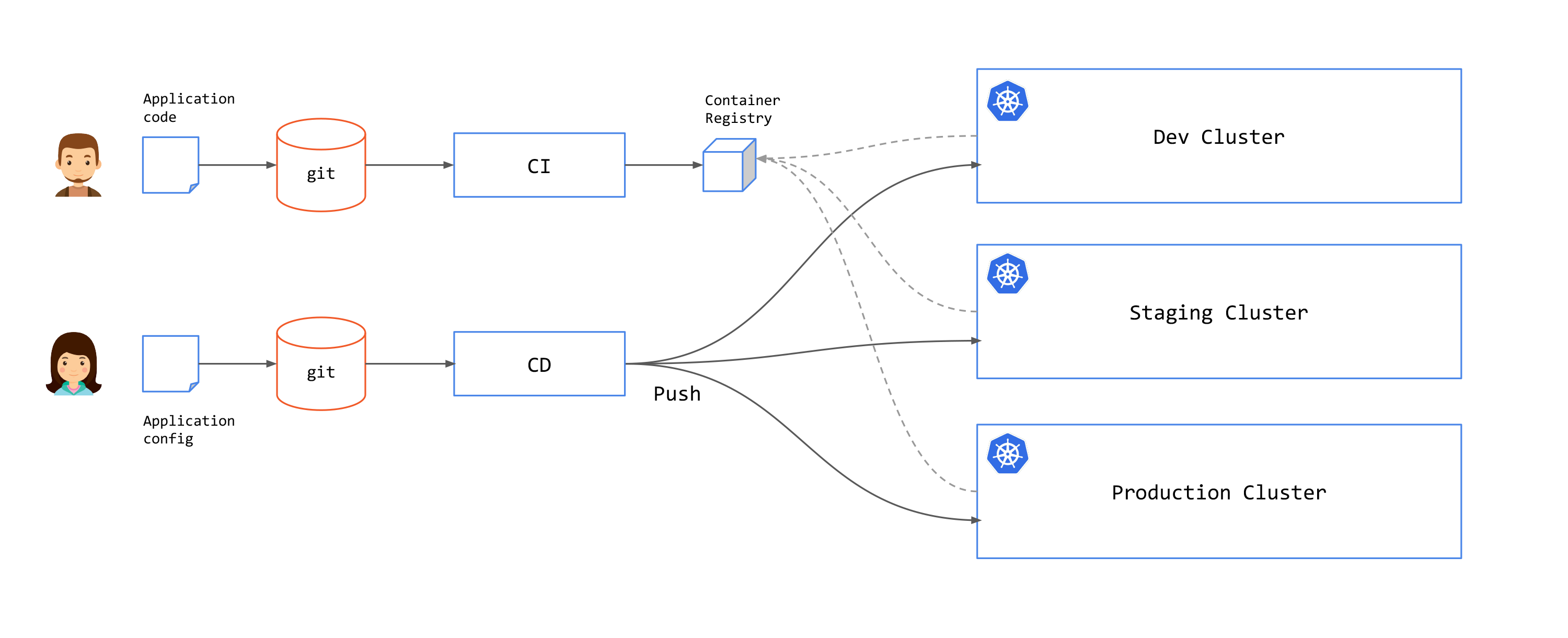
In the pull approach, an agent inside the destination cluster regularly scans the associated git repositories. If a change is detected, the agent updates the cluster state. In this case, the CD components are deployed within each cluster.
Examples of pull solutions include Argo CD and Flux.
For more information and commentary, refer to the following articles:
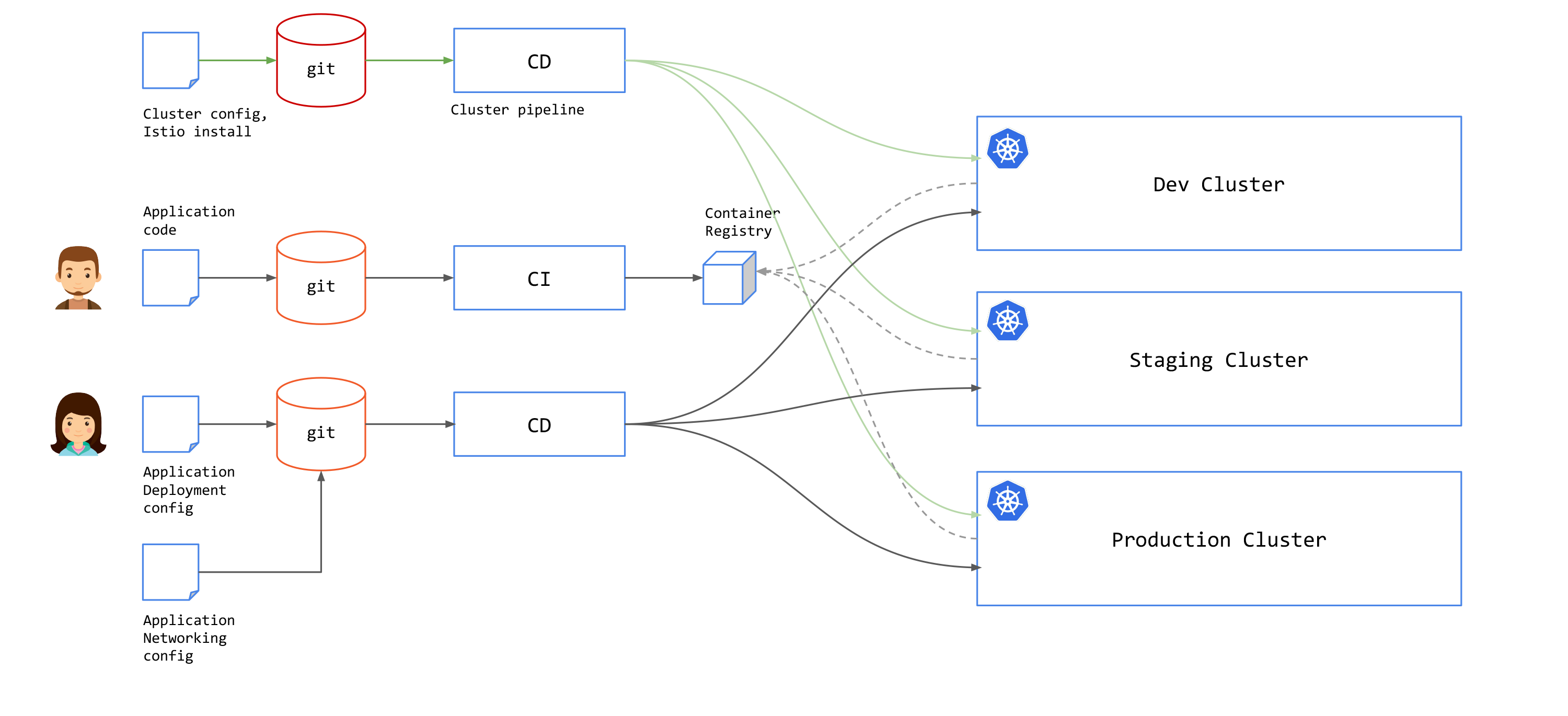
Provisioning Clusters
When operating at scale, you may even wish to provision Kubernetes clusters using a GitOps pipeline. This may involve creating the new cluster, and installing common infrastructure components into clusters: logging, monitoring, secrets, certificates, access controls, and service mesh components like the TSE control plane.
The Challenges of GitOps
Alongside the benefits, there are a number of challenges created by the GitOps approach that you may need to overcome or work around.
- GitOps breaks down with auto-scaling and dynamic resources. Since GitOps expects state to be stored in Git, dynamic aspects such as auto-scaling can cause problems when attempting to sync the state. Tools like ArgoCD have custom diffs to handle this.
- GitOps does not address promotion of releases between environments. Configurations for each environment will probably be stored in different Git branches. Templating solutions such as Helm and Kustomize are usually used to provide a base template that can be then customized on each environment.
- Auditing of actions can be problematic. While Git has the change history, it is hard to answer certain questions without additional tools to analyze data in multiple Git repositories. For example, "What percentage of deployments to environment X were successful and what had to be rolled back?" or "How many features exist in environment X but are not in environment Y yet?"
- Large scale deployment with large number of clusters and services can pose a challenge. Operations that affect a large number of resources such as adding a new company-wide label on all deployment may be problematic, as you may hit a problem of managing a large number of Git repositories and branches.
- Lack of standard practice. A good example where there still isn't a single accepted practice on how configuration should be managed is secrets. If secrets are stored in Git, they need to be encrypted, and thus will have to have their own workflow to process them during a deployment. If they are not stored in Git, then you no longer will be able to store your cluster's state in Git. In practice organizations tend to use external secret management tools such as Vault.
- Lack of visibility and runtime validation. Git does not provide visibility into what has happened during runtime. For example, if a single update causes updates in other dependent services, there's no easy way to find it out.
GitOps for Service Mesh
A Service Mesh makes it easier to adopt a GitOps practice because it provides a separate point of control for networking, security, and observability issues that is independent from the applications. Your application teams do not need to concern themselves with these runtime issues; rather, a separate operations team can define the runtime environment in a way that is not tightly-coupled to each application.
Since service mesh runs outside of your application, you will have another configuration that you need to add to your GitOps pipeline in addition to application deployment configuration. With Istio, this would be Istio resources, e.g. Gateway, VirtualService, DestinationRule and others.
GitOps for Tetrate Service Express
TSE simplifies and abstracts many of the Istio configuration constructs, building Istio configuration dynamically from a combination of desired intent (expressed through the TSE APIs) and runtime state (discovered dynamically from TSE's control planes).
TSE has two APIs: installation and configuration. The Installation API is used in provisioning the Management Plane and Control Plane clusters, and when deploying 'fixed' infrastructure such as Ingress Gateways. The Installation API is implemented with Kubernetes YAML files and can be added to cluster provisioning pipeline.
The Configuration API can be used in two ways:
-
TSE-native: Use the TSE API or use TSE CLI (
tctl) to apply TSE configurations to the TSE Management Plane. The Management Plane will distribute configurations to the Kubernetes clusters based on the specifiednamespaceSelector.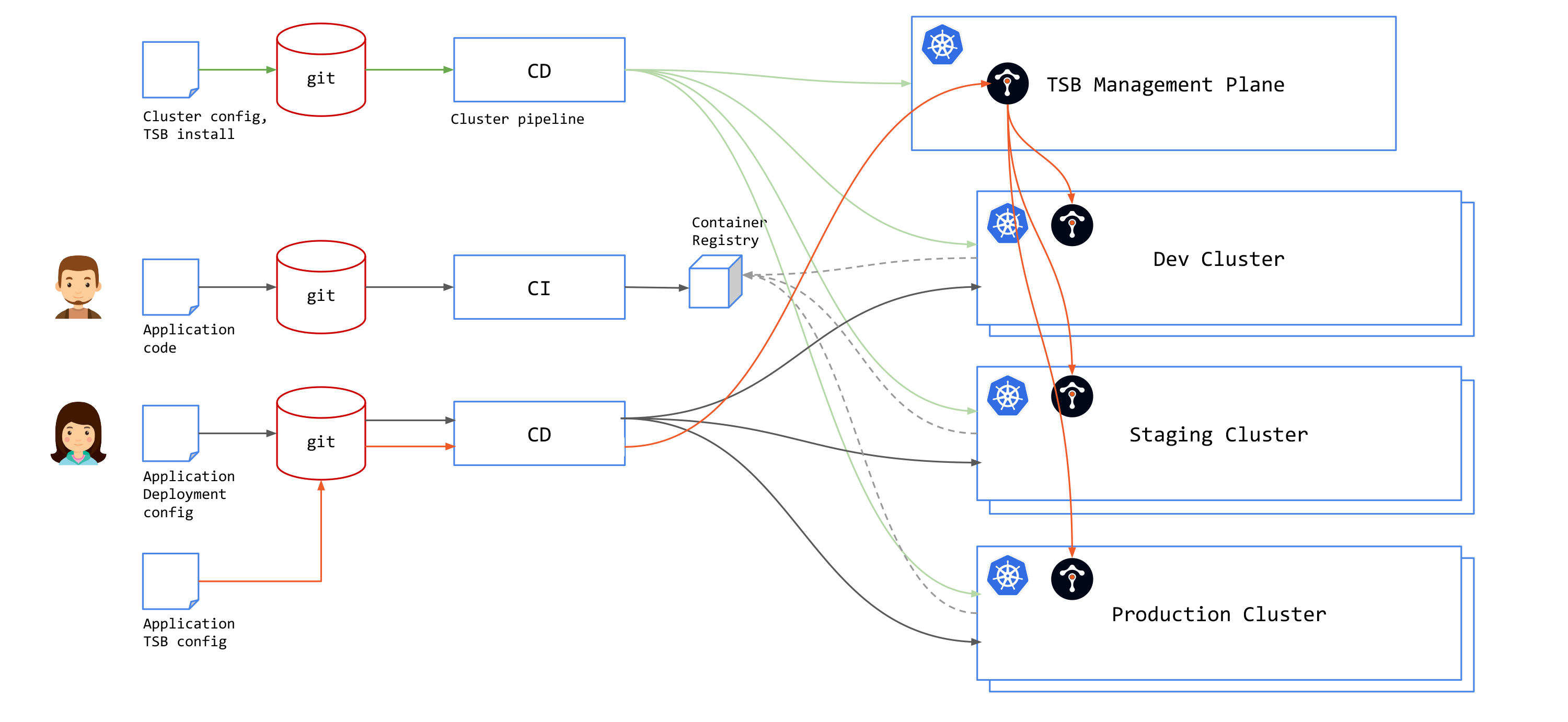
You will need to add
tctlto your CD pipeline, and correctly authorize it to write to your Management Plane. -
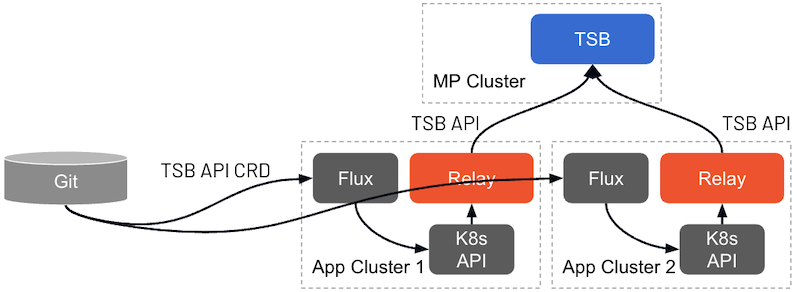
Kubernetes-based: TSE workload clusters can accept TSE configuration (they are "GitOps enabled") provided through the Kubernetes API. Each TSE configuration resource uses a slightly different API and schema, defined by a Kubernetes CRD (Custom Resource Definition).
With this approach, you can specific TSE configuration using native Kubernetes API resources in your CD pipeline.